About
Metrics matcher is a data testing tool.
It executes SQL queries against your data in a batch, compares expected and actual results and highlights mismatches and errors.
This is similar to running suites of test cases with assertions, but for databases.
This is how it looks on Windows:
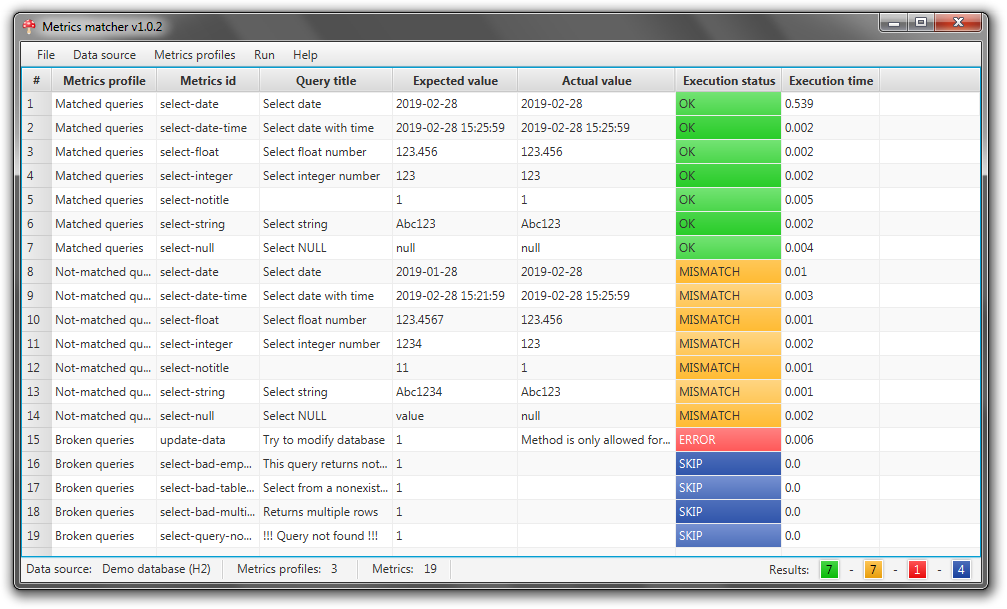
Metrics matcher is a Java-based desktop application. It requires Java 8 with JavaFX to be installed. For example it could be Oracle JDK 8.
It is open and free, licensed under MIT. With sources hosted on the GitHub in the metrics-matcher repository.
In order to start using of the application your need to:
- Download and unpack the latest version (see Releases)
- Configure database connections (see Data sources)
- Download JDBC driver for your database if need (see Drivers)
- Write your SQL queries (see Queries)
- Link data sources, SQL queries and expected results (see Metrics profiles)
- Run it
- See how the actual result matches the expected.
Releases
These versions of the application were released and now available for downloading:
- v1.0.3 (2020-06-04)
- metrics-matcher-1.0.3-core.zip
- metrics-matcher-1.0.3-demo.zip
- metrics-matcher-1.0.3-mysql.zip
- metrics-matcher-1.0.3-oracle.zip
- Added “Additional result” column to display extra information gathered together with a metrics
- SQL queries can be grouped into subdirectories
- Option to specify schema in database
- Synchronize action shortcut (Ctrl+R)
- v1.0.2 (2019-03-24)
- metrics-matcher-1.0.2-core.zip
- metrics-matcher-1.0.2-demo.zip
- metrics-matcher-1.0.2-mysql.zip
- metrics-matcher-1.0.2-oracle.zip
- Separate app builds
- Optimized app size
- v1.0.1 (2019-03-17)
- metrics-matcher-1.0.1.zip
- Initial implementation
Since v1.0.2 build procedure produces different variants of the app.
Latest release contains these variants of the app:
- core - minimal version without drivers and configs
- demo - includes H2 driver, different types of SQL queries and profiles to demonstrate how it works
- mysql - includes MySQL driver, data source template for MySQL database and dummy metrics profile
- oracle - includes Oracle driver, data source template for Oracle database and dummy metrics profile
Full list of downloadable files is available at Releases
Configuration
Data sources
Data source is a set of connection parameters to your database. You can define multiple data sources, but only one at a time can be selected as an active in the application.
In theory, the application supports any databases that have JDBC interface. Like: PostgreSQL, MySQL, MariaDB, Oracle, H2, etc. You just need to provide the appropriate driver (see Drivers section).
Data sources are defined in the configs/data-sources.json file.
Sample file:
[
{
"name": "My H2",
"url": "jdbc:h2:mem:dev",
"username": "me",
"password": "passwd"
},
{
"name": "My Oracle",
"url": "jdbc:oracle:thin:@//myhost:1521/orcl",
"username": "me",
"password": "passwd",
"timeout": 60,
"schema": "DEMO"
}
]
Optional connection timeout parameter can be specified in seconds (300 seconds by default).
Application establishes connection in READ-ONLY mode. So, the app does not allow queries to modify data in the database.
Drivers
Application interacts with databases via JDBC interface using JDBC driver.
Typically, JDBC driver is a Java library packed into the .jar file and supplied by the database vendor.
You may find appropriate drivers at Maven repository, like these:
Binary is available at the driver’s page in the Files section.
Here is a list of well-known JDBC drivers:
| Database | JDBC JAR | JDBC URL Template |
|---|---|---|
| H2 | h2-1.4.199.jar | See Database URLs |
| Microsoft SQL Server | mssql-jdbc-7.2.1.jre8.jar | jdbc:sqlserver://HOST;DatabaseName=DATABASE |
| MySQL | mysql-connector-java-8.0.15.jar | jdbc:mysql://HOST/DATABASE |
| Oracle | ojdbc8.jar | jdbc:oracle:thin:@HOST:1521:SID |
| PostgreSQL | postgresql-42.2.5.jar | jdbc:postgresql://HOST/DATABASE |
Drivers should be placed into drivers directory to be available in the app. You can put the drivers you need.
The application most likely should work with any database.
Queries
Application works with small portions of data extracted from the database using SQL queries.
Each query should return a metrics - it is a single value in a single row.
In most cases it is a counter or result of aggregation function.
Empty result or result set of multiple rows will be treated as an error.
SQL can be simple like:
-- Count of users
SELECT COUNT(1) FROM users
You can also use parameters:
-- Max age in the group ${groupName}
SELECT MAX(user_age)
FROM users
WHERE user_group = '${groupName}'
Query may have optional comment (started with --) on the first line.
In the runtime such parameters will be substituted with values specified in the Metrics Profiles.
Since version 1.0.3 it is possible to select extra information together with a metrics, like:
-- Max age in the group ${groupName}
SELECT MAX(user_age), COUNT(1) AS group_size, AVG(user_age) AS avg_age
FROM users
WHERE user_group = '${groupName}'
In such case a string like “GROUP_SIZE=123; AVG_AGE=25” will be displayed in an “Additional result” column. This additional value isn’t involved in the Expected/Actual comparison. It is only for display purposes.
Files with SQL queries should be placed into the queries directory. One query per file. Queries can be placed into subdirectories.
Metrics profiles
Metrics profile is a way to link queries with expected results and organize them into groups.
Metrics profiles can be defined in metrics-profiles.json, like this:
[
{
"name": "Portal users",
"metrics": {
"total-count-of-users": 125,
"average-user-age": 35.5,
"last-registration-date": "2019-02-28",
"last-event-timestamp": "2019-03-23 15:25:59",
"most-popular-user": "Neo"
}
},
{
"name": "Diablo gamers",
"metrics": {
"games/count-of-users": 55
},
"params": {
"groupName": "diablo"
}
}
]
Here metrics is a map of query ids and expected results.
Imagine you have a file queries/total-count-of-users.sql.
Then total-count-of-users (without .sql) is a Query Id.
And you expect that this query should return 123 users.
Note that if a SQL is placed into a subdirectory then Query Id should be specified with the subdirectory name as a prefix. So if:
- Subdirectory is “games”
- and SQL file name is “count-of-users.sql”
Then:
- Query Id will be “games/count-of-users”
Queries can be parameterized.
For example, if out have a query like:
SELECT COUNT(1) FROM users WHERE user_group = '${groupName}'
Then you can use the same query in different profiles:
[
{
"name": "Diablo gamers",
"metrics": {
"count-of-users": 55
},
"params": {
"groupName": "diablo"
}
},
{
"name": "Minecraft gamers",
"metrics": {
"count-of-users": 10
},
"params": {
"groupName": "minecraft"
}
}
]
For the first profile query will be formed as:
SELECT COUNT(1) FROM users WHERE user_group = 'diablo'
and for the second as:
SELECT COUNT(1) FROM users WHERE user_group = 'minecraft'
SQL metrics tips and tricks
Aggregate functions are the best for metrics. They produce single result based on a data from multiple rows.
COUNT, MIN, MAX, SUM, AVG are so trivial and very useful functions.
It seems that you are familiar with these functions if you use this app.
However, there are a few tricks to make the life easier.
Concatenation
You may want to match several metrics at once, using a single query. For example, MIN and MAX age. But in terms of the application the query should return a single value as “Actual result”.
No problem, just concatenate your multiple values into the single one.
Like this (Oracle dialect):
-- min-max-age.sql
SELECT MIN(age) || ' - ' || MAX(age) FROM users
And then declare metrics:
{
"metrics": {
"min-max-age": "11 - 89"
}
}
List aggregation
Sometimes it is necessary to match a list of unique values from the database.
Sounds like result contains multiple values, but again, it can be represented as a single value.
SQL (Oracle dialect):
-- user-groups.sql
SELECT LISTAGG (group_name, '; ') WITHIN GROUP (ORDER BY group_name)
FROM (SELECT DISTINCT group_name FROM users)
And the matcher:
{
"metrics": {
"user-groups": "The Bad; The Good; The Ugly"
}
}
Data checksum
It is a good idea to calculate checksum to control data integrity.
Different databases have different functions to do this.
On Oracle it is possible to calculate something similar to checksum:
-- users-checksum.sql
SELECT SUM(ORA_HASH(user_id || ';' || user_name)) FROM users
And the matcher:
{
"metrics": {
"users-checksum": 436640800921
}
}
Build
Sources of the app are open. You can modify and build it on your own. You can clone or download them from the GitHub.
Java 8 and Maven required to build the app using command:
mvn clean package
Output files (like metrics-matcher-*.zip) will be placed into the target directory.